
Durante el último trimestre de 2025, todo el equipo de YKSIOS hemos realizado una formación en #cienciadedatos. El objetivo era aprender técnicas y aplicaciones de análisis de grandes volúmenes de datos para luego utilizarlas con los que se generan en el marco de la actividad contractual del sector público, que es el ámbito al que nos dedicamos fundamentalmente en nuestra compañía.
El resultado ha sido impresionante. Como bien dice Kiko Llaneras, cuyo libro Piensa claro ha sido un complemento espectacular a la formación, “el mundo es un lugar complejo, y los datos te ayudan a descifrarlo”. Al aplicar esa reflexión a la contratación pública nos damos cuenta de que los datos cuentan historias que nos permiten entender muchas cosas, y sobre todo, nos ayudan a tomar mejores decisiones, basadas en evidencias. Sin datos, lo que quedan son meras opiniones.
He de reconocer que, con nuestra formación eminentemente jurídica, aproximarse a las técnicas y aplicaciones de ciencia de datos no fue tarea sencilla. Pero como compañía dedicada al Govtech, hay que predicar con el ejemplo. Así que abrimos el YKSIOSLAB y nos pusimos a trabajar. Lo primero -por influencia de nuestro origen académico que nunca olvidamos- definir el método de trabajo. En este caso seguimos el marco de referencia CRoss Industry Standard Process for Data Mining (CRISP-DM), que define las fases del ciclo de vida de un proyecto de big data.
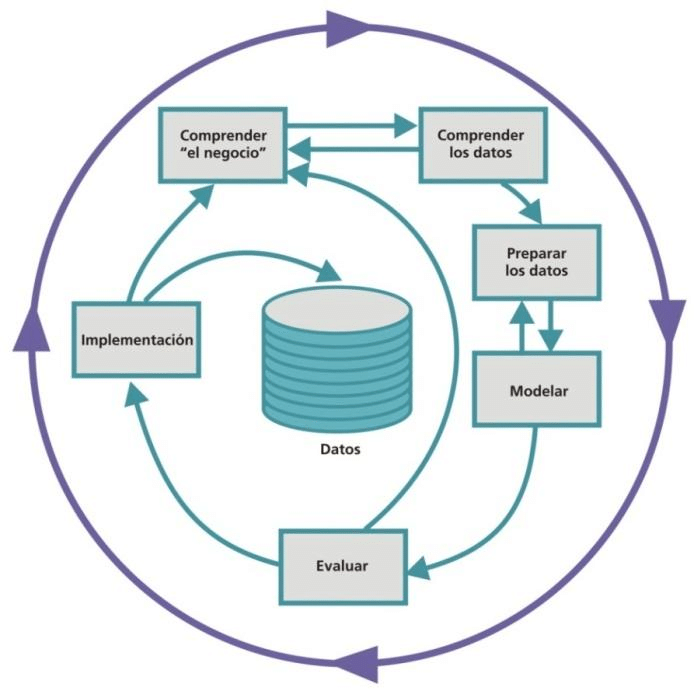
En primer lugar, hay que comprender “el negocio” de la contratación pública. Esta parte era “sencilla” para nosotros. Después de acumular casi veinte años de experiencia en esa materia sabemos identificar algunos problemas que se plantean en su práctica. Pero a partir de aquí empieza la cuesta arriba. ¿Qué conjuntos de datos (datasets) tenemos o necesitamos de la contratación pública en España? ¿Dónde están? ¿Cómo de fácil -o difícil- es obtenerlos? ¿sabemos manejar los formatos en los que se encuentran, como por ejemplo, un fichero Atom? La conclusión a la que hemos llegado es que acceder a datasets abiertos sobre contratos públicos no es sencillo, pero una vez obtenidos, todavía se plantea otro problema aún mayor: ¿Qué calidad tienen esos datos? ¿Son datos íntegros y completos? La respuesta la podemos imaginar, así que el tercer paso es el de preprocesar los datos obtenidos para limpiar, transformar y homogeneizar el dataset.
Después de todo eso, que puede ocupar tranquilamente el 60-70% de un proyecto de datos, empezamos con el modelado (y la obtención de los primeros resultados). En esta fase hemos aprendido a utilizar algunas herramientas de visualización de datos superpotentes, como Power BI. Y de repente… los datos toman forma de diagramas de barras, histogramas, gráficos de series temporales o de dispersión (scatterplot)…
En ese momento los datos te ayudan a comprender la complejidad de la contratación pública.
Y a partir de ahora ¿qué? Pues después de la formación aún nos queda trabajo por hacer. Evaluar nuestro modelo, compararlo con otros que se ajusten mejor a los objetivos definidos inicialmente, y finalmente su despliegue (puesta en producción) en alguna entidad que se atreva a usarlo, servicio que ofreceremos próximamente (los interesados nos pueden contactar a través de yksios.es o info@yksios.com).
De momento, lo que hemos hecho ha sido darle todo el material que hemos generado durante la formación a la inteligencia artificial para que nos hiciera un videoresumen…. y os compartimos el resultado.
